Begriffsklärung: Character Set
Ein Zeichensatz, englisch Character Set, kurz charset,
ist eine festgelegte Sammlung von Schriftzeichen, Zahlen, Symbolen, in dem jedem enthaltenen Zeichen eine eindeutige dezimale Zahl zugeordnet ist.
Der ASCII-Zeichensatz besteht z.B. aus 128 Zeichen: 33 nicht druckbaren sowie den folgenden 95 druckbaren Zeichen, beginnend mit dem Leerzeichen:

Begriffsklärung: Character Encoding
Die Zeichenkodierung, englisch Character Encoding, legt die
eindeutige Zuordnung jedes einzelnen Zeichens innerhalb eines Zeichensatzen fest.
Der deutsche Umlaut Ü wird zum Beispiel im ISO-8859-1-Zeichensatz
mit dem Dezimalwert 220 kodiert.
Im EBCDIC-Zeichensatz kodiert derselbe Wert 220 die geschweifte Klammer }.
Zur Korrekten Darstellung eines Zeichens muss also die Zeichenkodierung bekannt sein,
der Zahlenwert alleine reicht dafür nicht aus.
Nur so kann der Browser wissen, ob mit 220 das Ü oder die geschweifte Klammer } gemeint ist :)
Bzw. welche Abfolge von 0 und 1 welches Zeichen ergibt:
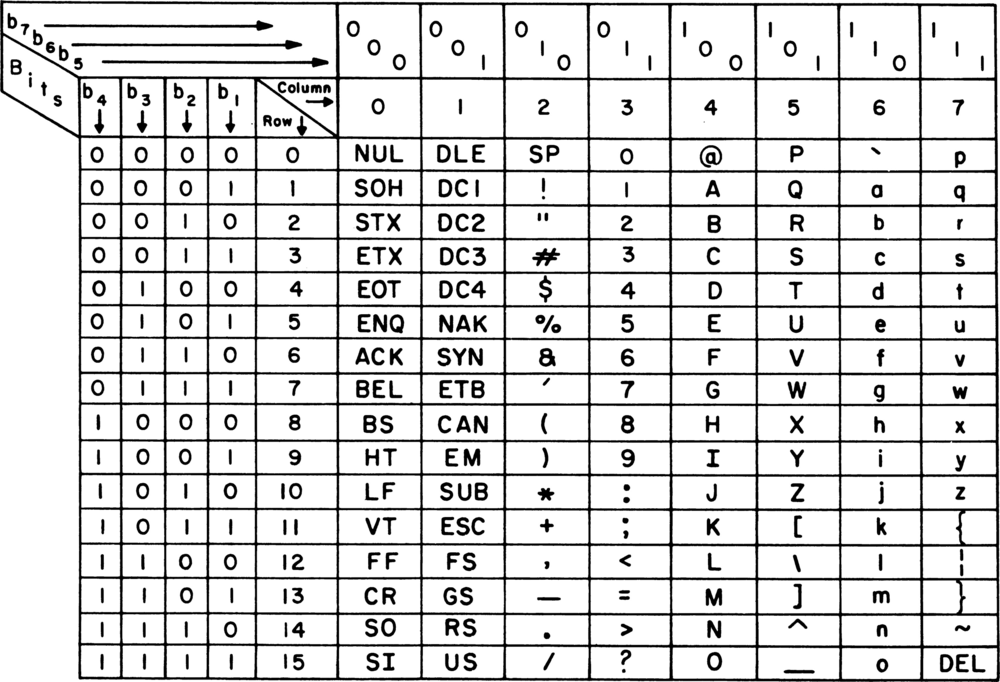
Begriffsklärung: HTML Entities
Eine HTML-Entität, englisch HTML entity, ist eine eindeutig abgrenzbare Zeichenfolge mit spezieller Bedeutung, die in HTML verwendet wird, um spezielle Sonderzeichen, Symbole, Schriftzeichen etc. unabhängig vom Zeichensatz und dem Encoding darzustellen.
Es gibt benannte und numerische Entitäten, der Aufbau besteht aus dem Startzeichen &,
gefolgt von dem Code, gefolgt von dem Endzeichen ;.
Beispiele benannt:
ergibt " " ⇒ nbsp steht für non-breaking space
& ergibt & ⇒ amp steht für Ampersand
€ ergibt €
Beispiele numerisch:
© ergibt © ⇒ dezimales Format
∞ ergibt ∞ ⇒ hexadezimales Format
Eine Tabelle mit den verschiedenen Entities findet ihr hier.
Anwendung
Der Standard-Zeichensatz heutzutage ist UTF-8, bitte verwendet diesen auch in allen euren Beispielen sowie in der Projektaufgabe. Wer sich ausführlich informieren möchte: https://de.wikipedia.org/wiki/UTF-8
Ganz am Anfang war ASCII der Standard, ein 7-bit Zeichensatz, mit dem nur 128 Zeichen dargestellt werden können.
In Windows wurde der Windows-1252 Zeichensatz verwendet, eine Kopie von ASCII, aber mit 8-bit, weshalb dort 256 verschiedenen Zeichen dargestellt werden können.
In HTML4 wurde dann u.a. der ISO-8859-1 Zeichensatz eingeführt, der den ASCII-Zeichensatz um internationale Sonderzeichen erweitert. Je nach benötigten Sonderzeichen gibt es aber weitere ISO-8895-Zeichensätze, z.B. ISO-8895-7 für griechische Sonderzeichen.
Seit HTML5 wird die Verwendung von UTF-8 empfohlen
Zu guter Letzt findet ihr hier noch ein Beispiel mit falschem Encoding, bei dem die Sonderzeichen nicht richtig dargestellt werden, sonder nur die verwendeten Entities.